MySQL 的事务隔离级别分为四种:
- 未提交读,当前事务在没有 commit 的时候,修改的数据可以被其他正在运行的事务读取到,这种情况下数据会产生脏读的表象;
- 读提交,只有事务在 commit 以后,修改的数据才能被其他事务看到,但由于并发的问题可能会产生数据的幻读问题;
- 可重复读,事务在启动的时候会创建一个读视图的快照(read-view),在事务执行期间,即使有其他事务修改了数据,事务看到的仍然跟在启动事务的时候看到的数据一样。这是 MySQL 的默认事务隔离级别。
- 可串行化,事务必须在一个事务执行完成之后才能提交。跟串子一样,并发行极低。
MySQL 通过表锁和行级锁来解决数据的并发问题,事务在 update 操作的时候,会拿到影响数据行的读锁,在修改数据的时候不允许其他线程同时修改只能被迫等待,只有在当前的事务 commit 后才会释放读锁,此时其他的线程才能拿到锁。那么既然事务已经启动了,那么当其他线程去访问、修改行数据的时候,读到的又是什么值呢?当我们使用begin/start transaction 命令去启动事务的时候,这个时候事务还并没有完全的启动,只有在访问表的时候,事务才是真正的启动才会去创建基于全库的读视图,但是如果需要立即启动一个事务就需要使用 start transaction with consistent snapshop 这个命令。
那当我们在 navicat 工具的 SQL 窗口直接执行 update 的语句的时候,会有事务吗?虽然我们没有显式的使用begin/commit 语句,但这个 update 的语句本身就是一个事务。当autocommit 的参数为 1 时,表示在 update 语句完成时会自动提交事务(由autocommit参数控制)。那么当执行 select 查询的时候会有事务么?答案是肯定的,在可重复读的情况下,select 访问表之前会自动创建一个全库的读视图,select 语句查询的是读视图的数据。
在 MySQL 里,有两个“视图”的概念:
- 查询视图,也称为“view”。是一个用查询语句定义的虚拟表,在调用的时候执行查询语句并生成结果。创建视图的语法是“create view SQL语句”,它的查询方式与表的使用是一样的,不同的是查询视图中的数据不能像表一种使用 update 对进行修改。
- 另一个是 InnoDB 在实现 MVCC 时用到的一致性读视图,即 consistent read view,用于支持 Read Committed(读提交)和Repeatable Read(可重复读)隔离级别下的实现,作用是在事务执行期间用来定义“我能看到什么数据”。
MVCC 支持 RC 和 RR 的隔离级别的实现,RR 隔离级别下会在事务启动时创建一个基于全库的快照,但是并不会拷贝全库的数据。在 InnoDB 里面每个事务有一个唯一的事务 ID(transaction id),是在事务开始的时候向 InnoDB 的事务系统申请的,transaction id 是按照申请顺序严格递增的。每个数据版本的事务 ID 记为row trx_id(行事务ID)。这个数据行变更的信息会记录在undo log的回滚日志文件里。数据版本是通过当前版本的事务ID 和undo log日志文件计算出来的,也就是通过 trx_id 往前推,每个事务 ID 就是一个数据版本的记录。
在可重复读的隔离级别下,一个事务启动的时候,可以看到所有已经提交的事务结果。但是在事务的执行期间,在事务启动之后的其他事务的更新它是看不到的,这个怎么实现的呢?以事务的启动时间为准,数据的事务版本在我之前生成的,就能看见;在我之后生成的,我就不认,只找当前事务ID 的上一个事务版本。在技术实现上,InnoDB 为每个事务构造了一个一致性视图的数组,用来保存事务启动的时候有哪些已经启动了但还没有提交的所有事务ID,也包含事务本身的ID。数组里面已经提交的事务 ID 的最小值记为低水位,已经创建过的事务 ID 的最大值 +1 记为高水位,低水位 ➕ 高水位就组成了所有活动事务的集合。通过获取当前的事务ID 去遍历小于当前事务ID 的数据版本就好了。
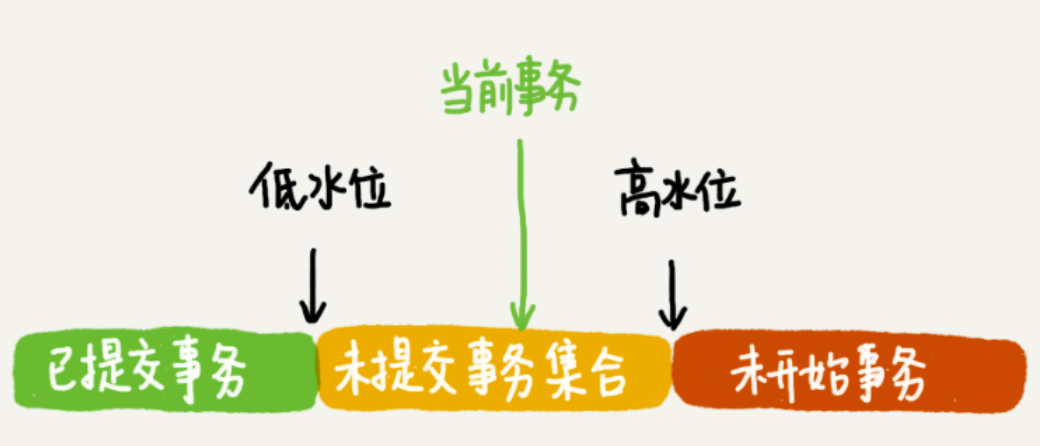
- 绿色部分:表示这个版本是已提交的事务或者是当前事务自己生成的,这个数据是可见的;
- 红色部分:表示这个版本是由将来启动的事务生成的,不可见的;
- 黄色部分:如果trx_id在数组中,表示这个版本是由还没提交的事务生成的,不可见;如果 trx_id 不在数组中,表示这个版本是已经提交了的事务生成的,可见。
因为 InnoDB 的 MVCC 机制利用了多个数据版本的特性,所以只会创建已提交事务和未提交事务的快照,所以就算 100G 的数据创建的快照也会非常快。
以这个图为例:
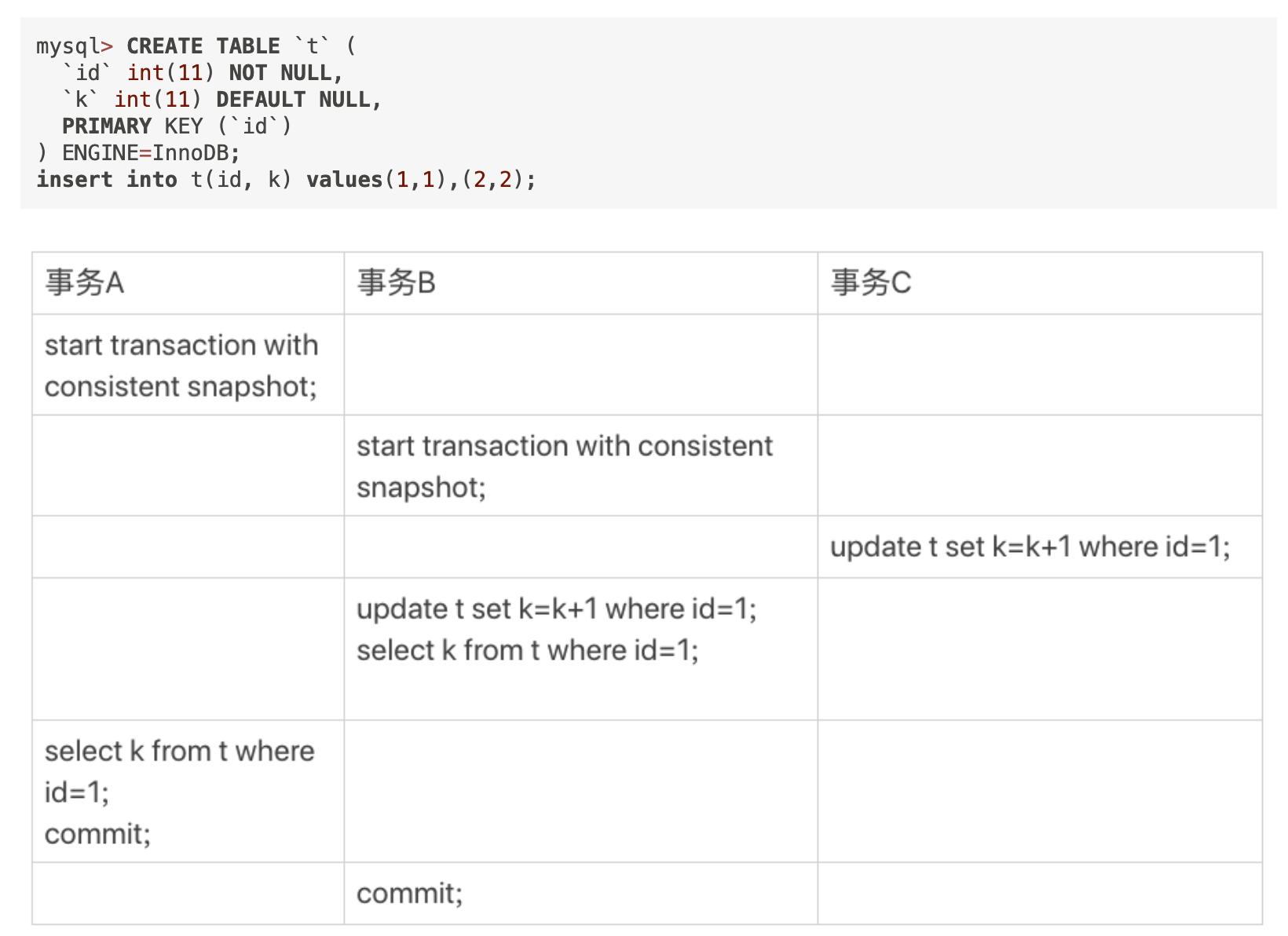
事务 A:使用了start transaction with consistent snapshot,这个命令执行后会立即创建一个只读的视图;
事务 B:也使用了start transaction with consistent snapshot 这个指令,也在命令执行后创建一个只读的视图;
事务 C:虽然只有一个 update 的语句,但其实这个语句在执行时也会创建一个事务,且这个事务就是这个语句的本身,当 update 执行完成后,如果 autocommit 的参数为 1 则可以自动提交,那么读锁就会释放;
所以,在此时数据库里已经有一条 id 为 1 的行记录,那么在事务 C 完成后,此时的id 为 1 的行记录的 k 值为 2。
事务 B 此时因使用了with consistent snapshot指令,所以这里事务 A 因为通过 update 去更新时发现id 为 1 的 k 值已经被事务 C 更改了,所以会在事务 C 的基础上继续更新 k 值,所以事务 B 读到的id为 1 的值是 3,不然事务 C 的值就会被覆盖掉;
事务 A with consistent snapshot指令创建一致性视图后,select 查的是事务启动时创建的一致性视图,所以查询到 where id=1 的值为 1,此时如果事务 A 想要看到事务 C 的 更新,可以使用 lock in share mode 或者 for update 排他锁来通过读锁获取事务 C 更新记录,但此时事务 B 没有通过 commit 来提交,所以无法看到事务 B 的更新;
通过一致性视图分析就是:
注意:假设id 为 1的 trx_id为 100;
- 事务 A 创建时(事务ID 为 1000),事务B 和事务 C 都还没有创建,所以事务 A 的活动事务只有其本身:1000;事务 B创建时(事务ID 为 1001),事务 C 还没有创建,所以事务 C 的活动事务为:1000,1001;事务 C 创建时(事务ID 为 1002),活动事务为1000,1001,1002;
- 事务 C 因为是单独的 update 语句,所以id为 1 的k 值 变更为 2,此时id 为 1 的 trx_id的版本为1002;
- 事务 B 执行时因为 start transaction with consistent snapshot创建了一致性视图的快照,快照中的 trx_id的版本号为 100,但当 update 更新时发现id 为1的 trx_id为 1002,所以只能在事务 C(trx_id为1002)的基础上修改数据,这个过程称之为当前读,因为更新数据都是先读后写的,否则事务 C 的版本就会被覆盖。那么视图 B 修改后的id 为 1 的 trx_id 变更为 1002,但是此时事务 B 的数据并没有提交,所以对其他事务不可见,因为事务 B 的版本号 trx_id=1001 大于事务 A 的版本号 trx_id=1000;
- 事务 A通过start transaction with consistent snapshot创建了一致性视图,所以 select 的操作是在一致性视图中查询的,所以此时 select 查询的还是一致性视图快照内容,此时 id=1 的 trx_id为 100,而事务 A 的trx_id为 1000,所以事务 A 看到的k 为值 1;
问题:
- 事务在启动时候创建的读事务快照会不会很大?如果数据量很大的话,快照会不会占用很大的内存空间?
不会,因为一致性视图创建的是当前数据库中的活动事务,也就是所有小于当前时间节点的已启动,但没有提交的事务。
- 事务启动后,其他的线程去访问和修改数据,此时其他的线程读到的值是什么?读到的是其他已提交事务,且事务ID 是在当前活动事务id 之前的事务或者是自己的事务。
主要看事务级别和事务的语句顺序,如果不通过 with consistent snapshot特殊定义且事务隔离级别在可重复读的情况下,事务只会在第一条操作表的语句执行后创建一致性视图。如果通过with consistent snapshot来指定的话,会在start transaction with consistent snapshot语句执行后,立即创建当前数据库中的活动事务快照。
- start transaction 表示启动一个事务,那么with consistent snapshot 有代表什么意思,有什么作用?
start stransaction 表示启动一个事务,只有在执行到第一条访问表的语句时,事务才真正启动;如果需要立即启动事务,就需要加with consistent snapshop;
- MVCC 支持 RC 和 RR 隔离级别,在 RR 隔离级别下会通过 MVCC 创建全库快照,那么 RC 级别是不是也一样?那为什么 RC 级别还是会存在幻读的问题?
RR 级别在不特殊指定的情况在,会创建一份一致性视图快照,在 RC 级别来,每次查询都会创建一次一致性视图快照。
- MVCC 的不同数据版本保存在那里,因为不管对 update 去修改几次,表中都只会有一条数据,那么变更的记录记在哪里?如何能看到多个版本的数据信息?
MVCC 的不同数据版本保存在undo log的日志文件中,表中有一个不可见字段trx_id用来记录数据的事务变更,事务变更记录在 undo log 日志文件中,通过行记录的回滚指针来记录在 undo log 中的偏移位置。
- transaction id如果分配不是递增的会怎么样?
事务会根据trx_id来寻找多个数据版本,如果 trx_id不是自增且顺序的,会导致数据的版本错乱。
- 如果同时有多个事务在执行,且都在当前事务启动之前启动,那么事务是怎么处理的?
在可重复读(RR)的级别下通过trx_id来区分,在不涉及 update 操作的情况下且没有通过with consistent snapshot立即创建一致性视图的情况下,以第一条语句访问数据表的时间为准创建一致性视图,后续的操作查询的都是一致性视图的快照内容。
- MVCC 的全库快照是所有已提交数据的,还是受影响的行数据范围的快照?
MVCC 的全库全照,也就是一致性视图只是记录了当前数据库中没有提交的活动事务。跟行记录没有关系。用于区分在多线程的情况在,不同的用户线程能看到哪些内容。